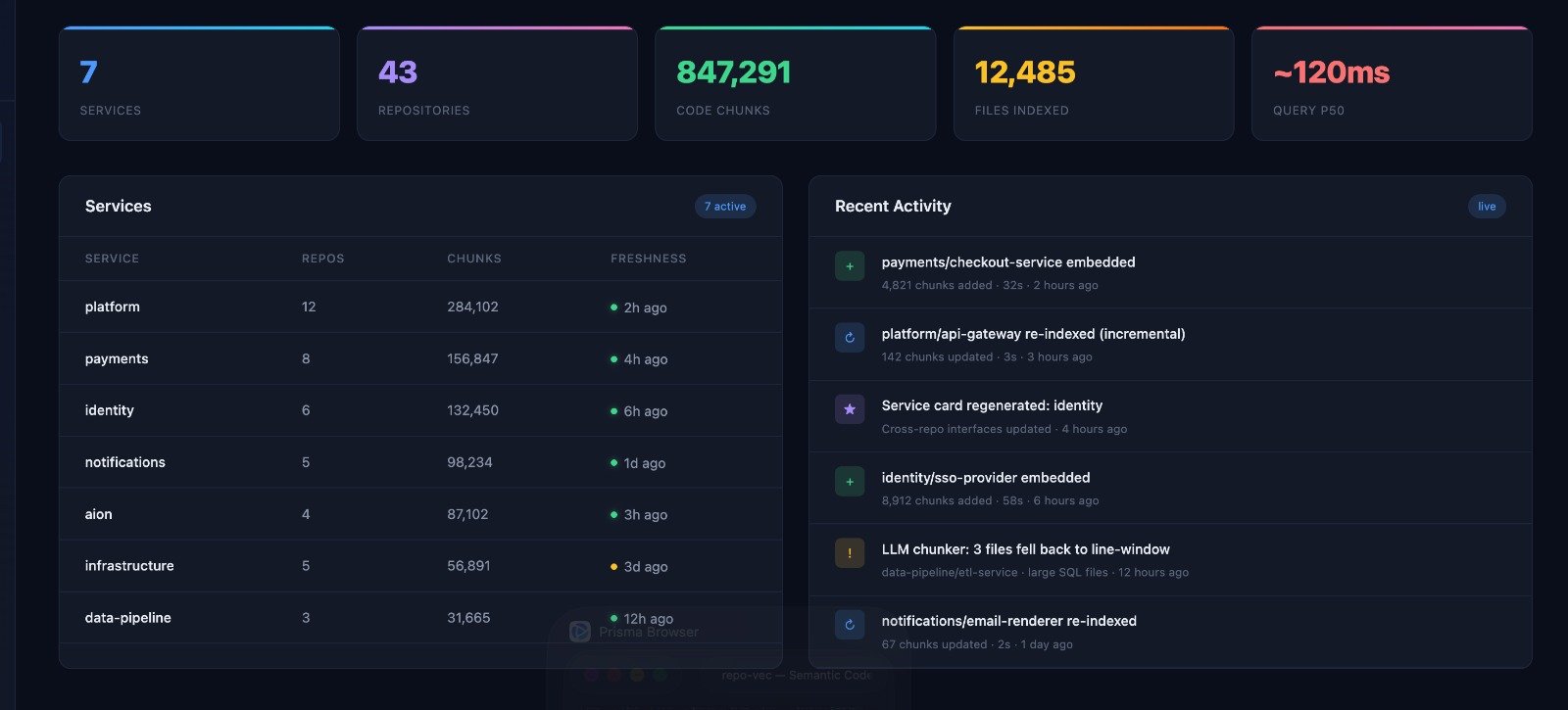

TL;DR
AI coding assistants are great at writing code and bad at writing the right code when the answer lives in another repository. Ask an agent to add a feature that should reuse a shared abstraction in one of your 50 repos, and it will grep through three of them, fill its context window, give up, and write a duplicate from scratch.
This isn’t a model problem. It’s an information access problem. A senior engineer doesn’t grep 50 repos to find the HMAC validator - they know where it lives. Give an agent that same recall by letting it query a pre-built index of the codebase instead of walking the filesystem, and first-try PRs go from “rejected, we already have this” to “approved.”
A note on the code below: every snippet here is pseudo-code, written to convey the idea, not the implementation. The real system is proprietary, so the actual interfaces, names, and internals are intentionally left out.
The problem: blind navigation
Picture a team with 50 repositories in a microservices setup. An agent gets a task: “Add webhook signature validation to the event ingestion service.”
To do this correctly, the agent needs to answer questions that span the whole codebase:
- Do we already have an HMAC validator somewhere?
- Which repo owns it? What’s the constructor signature?
- How do other services use it? What error types do they throw?
- What’s the team’s convention for middleware?
A traditional agent attacks this by walking the filesystem - find, grep, cat, one repo at a time. And every file it opens gets shipped up to the model as tokens. That’s the part people miss: each cat isn’t free reading, it’s data pushed into the model’s context, which costs money on every call and crowds out the room the agent needs to actually think (the same context-as-budget dynamic I unpack in Claude Code on a token diet). So it reads hundreds of files, burns budget doing it, fills its context window after three repos, and abandons the other 47. The result: a brand-new validator, the wrong error types, and a PR rejected with “we already have this in shared-utils.”
The model was capable. It just couldn’t see the codebase.
The insight: query, don’t walk
A developer who’s been on the team for years doesn’t scan every repo when they need something. They recall where it lives. They recall the pattern. They ask “who uses this?” and answer from memory in seconds.
That’s the capability an agent is missing. Not the ability to read everything - that doesn’t scale - but the ability to ask and get a precise answer: which functions, classes, and interfaces exist, and how they relate.
So the move is to build that recall ahead of time. Index the codebase once, into a structure an agent can query in a single call, and the “walk 50 repos” problem disappears.
How the recall gets built
The idea splits cleanly into two phases.
Offline - building the index. Each repo gets parsed into its natural semantic units: functions, classes, methods, interfaces. Not arbitrary line windows - a function split across two text chunks is useless for search. A parser walks the syntax tree and emits one chunk per real unit, with its metadata attached:
walk the parsed syntax tree:
for each node that is a function / method / class / interface:
emit one unit, carrying:
- its name and kind
- the class it lives in (for sibling lookups later)
- its signature and line range
- its source text
Each chunk is then embedded - the source text is turned into a dense vector (a list of ~1024 floats) that captures its meaning, so semantically similar code lands near it in vector space. That’s what lets “how does auth work” surface auth code even when the word “auth” never appears in it:
for each unit:
vector = embed(unit.source) # meaning -> ~1024 numbers
store in the index:
- the vector # meaning-based search
- the source text, searchable # exact-name / keyword search
- the metadata # signature, parent, lines, imports
Storing the raw text alongside the vector is deliberate: it gives a second way in. A query like HMACValidator.validate should match the exact symbol by name, not by vibes. So every unit is findable two ways at once - by meaning (the embedding) and by exact name (a keyword index over the text). Identifier-aware tokenizing splits camelCase and snake_case so symbol names survive intact.
This whole pass runs automatically when a pull request is merged - the moment the codebase actually changes is the moment the index updates. It’s incremental, too: file-level hashing means only the files touched by that merge get re-parsed and re-embedded. The agent never pays for any of it at query time.
Online - the agent asks. When the agent needs something, the query is embedded the same way and matched against the index across all repos at once. Two strategies run together - dense vector similarity for meaning, keyword scoring for exact identifiers - and their results are fused into one ranked list. The agent gets back the relevant code in seconds. No cloning. No file reads. No exhausted context.
The part that actually matters: developer cards
Finding the matching code is step one. It’s not the valuable part.
When the agent finds HMACValidator, a snippet of its source isn’t enough to design against. The agent still doesn’t know what the constructor takes, what methods are exposed, what exceptions to expect, or how the dozen other services that already use it actually call it.
So the index returns more than a snippet. It returns a compact profile of the symbol: its interface (constructor arguments, method signatures, what it raises), the call sites across every repo that uses it, the sibling methods on the same class, and a one-line note on what the file does:
HMACValidator (lives in shared-utils)
how to build it ...constructor args, with defaults
what it exposes ...the public methods and their shapes
what it throws ...the errors to expect
who already uses it ...a handful of real call sites, across repos
what the file is ...one line of context
# roughly - the exact fields are an implementation detail
With that profile in hand, the agent knows: import from shared-utils, pass a secret, call .validate(), catch InvalidSignatureError - and it can see that three other services all wire it into a middleware pattern. It designs against reality instead of guessing.
That profile is assembled from data captured at index time plus a couple of fast lookups. It costs milliseconds and zero extra model calls.
The agent workflow
A properly equipped agent settles into a simple rhythm:
- Orient. Ask what repos exist and what they’re for, and how the major interfaces connect across services.
- Search. Pull the relevant code with its full profile attached.
- Design. From the profiles, decide what to reuse, which patterns to follow, and which interfaces to implement against.
- Implement. Write against the real state of the codebase, not hallucinated assumptions.
The agent never clones a repo, never opens a file, never burns its context window crawling. It asks the index and gets exactly what a design decision needs.
Why a skill and a CLI, not an MCP server
The obvious way to hand a capability to an agent today is an MCP server. When I was building this, I deliberately went the other way. The interface is a plain command-line tool, plus a thin skill that teaches the agent when and how to reach for it. Two reasons, both about not wasting the thing that’s scarcest - context.
MCP tools are always-on context tax. Every tool an MCP server exposes ships its full schema - name, description, every parameter - into the model’s context at the start of every turn, whether the agent uses it or not. A handful of richly-documented query tools can quietly eat thousands of tokens before the agent has read a single line of the task. That’s the exact budget the tool is built to protect. A CLI costs nothing until it’s invoked, and the usage instructions live in a skill that the agent loads only when the task actually looks like a cross-repo design problem. Idle capability, idle cost.
A CLI hits more precisely. A command with explicit flags forces the agent to commit to a precise request - this service, this query, enriched or not - and the result comes back as a clean, parseable payload it can act on directly. There’s no chatty round-trip, no loosely-typed tool call that the model has to narrate around. Ask sharply, get exactly that back, spend the saved tokens on the actual design work.
The skill is the glue. It’s a short instruction set that lands in Claude Code or a similar agent and says, in effect, “when you’re about to design across repos, query the index first, here’s the shape of the call.” The agent reads it on demand, uses the CLI, and otherwise carries zero overhead for a capability it isn’t using this turn.
The payoff: first-try PRs
The difference shows up in review.
Without this kind of recall, agents ship implementations that duplicate abstractions they didn’t know existed, use the wrong error types because they never saw the convention, and break integration patterns because they never checked how anyone else uses the interface. Each one costs a rejection and a revision cycle.
With it, the first implementation reuses what’s already there, follows the conventions visible in the existing call sites, and integrates cleanly because the agent knew the constructor arguments and error types up front. It gets approved on the first pass.
The tech stack, briefly
The shape of the system matters more than the exact components, but the pieces are worth naming:
- Parsing: a tree-sitter-based pass for the common languages (Python, TypeScript, Go, Java, Rust, and a dozen more), with an LLM fallback for everything tree-sitter doesn’t grammar - Dockerfiles, compose files, playbooks - to pull out logical units and their metadata.
- Embeddings: a hosted text-embedding model producing ~1024-dimension vectors. This is the one place real money is spent at index time, which is exactly why it runs offline and incrementally rather than per query.
- Storage and search: Postgres with
pgvector- an approximate-nearest-neighbour index for the dense vectors, and a keyword index over the stored text for exact-symbol matching. The two result sets are fused with rank fusion, so there are no hand-tuned weights to babysit. - Card summaries: a small, fast model writes the one-line file and repo summaries at index time. Nothing on the query path calls a model at all.
At a rough scale of a couple hundred thousand vectors per service, a fully enriched query comes back in roughly a tenth of a second. The enrichment - callers, siblings, file context - is plain database lookups against data captured during indexing, so it adds milliseconds and zero model calls.
What this means
The bottleneck for AI-assisted development isn’t code generation. It’s code understanding at scale. An agent that can write a function but can’t find the existing one it should be reusing is worse than useless - it manufactures tech debt.
Give the agent recall over the whole system - what exists, how it’s used, how it connects - and the equation changes. Instead of agents that write code in isolation, you get agents that design with awareness of the full topology. They make architectural decisions grounded in what’s actually there.
That’s the difference between an AI that writes code and an AI that writes code that ships.